A kind of Cellular Automata Language Model. Inspired by Dave Ackley's asynchronous MFM work. What if a language model operated on a 2D grid instead of a 1D sequence? Context comes from spatial neighbors, not previous tokens. The grid wraps toroidally (pac-man style), so there are no edges.
The idea is train a small model that takes a position on a grid and the characters in the surrounding cells (of some manhattan distance), and predicts what should be in the center. Then let it loose on a blank grid. An event fires at some position, the model reads the neighborhood, writes a character, and moves on. Text emerges out of nothing and keeps evolving as the model revisits cells.
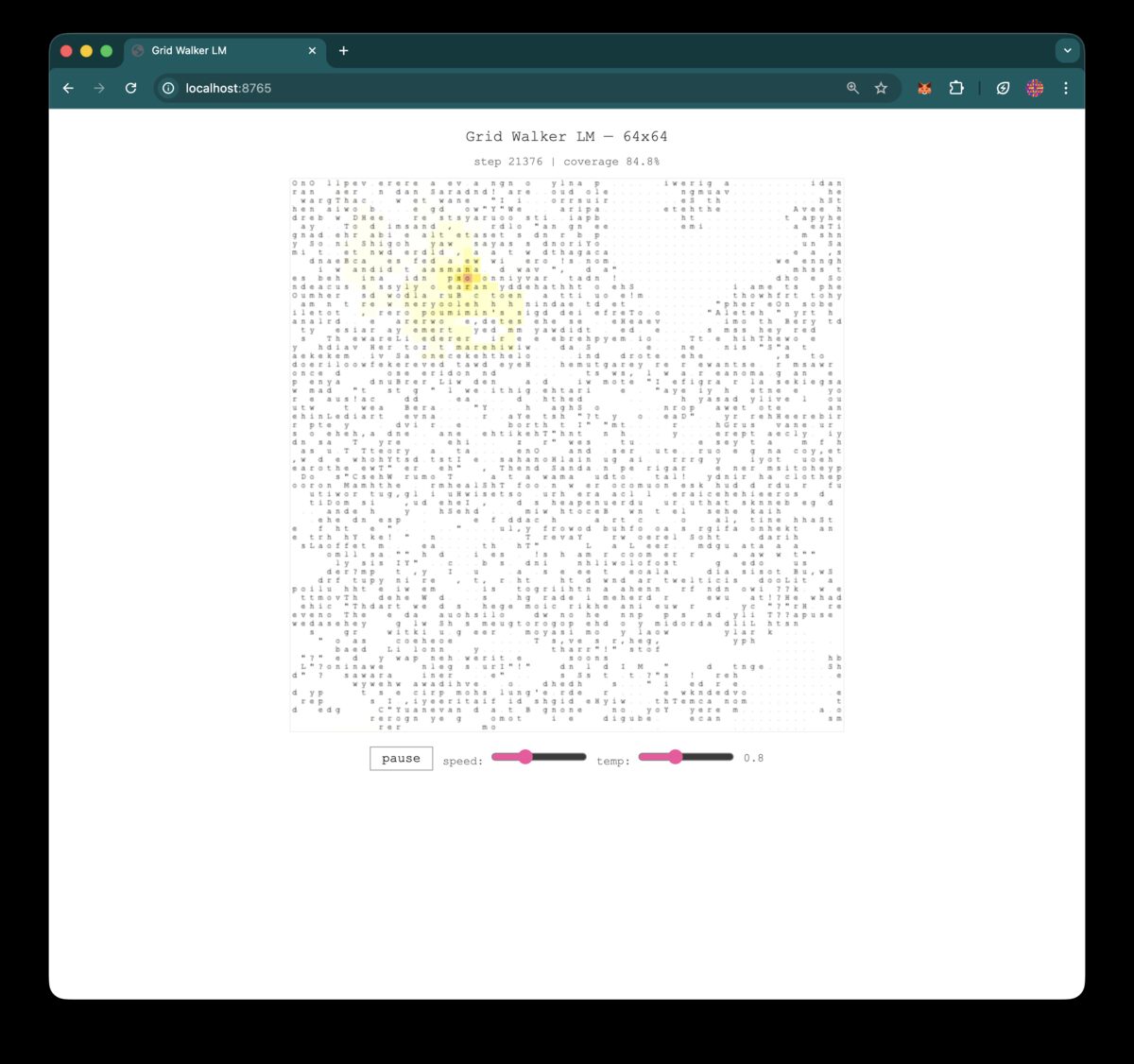
v1: English (the proof of concept)
64x64 grid, byte-level tokenization (257 vocab), trained on TinyStories. A "walker" wanders the grid randomly, observing its 4 cardinal neighbors, predicting the next character to place. Causal transformer over the walk history (512 steps), 6 layers, 384d.
v2: Chinese
Switched to Chinese characters as tokens. Each one is a meaningful semantic unit, unlike English bytes. Used adam89/TinyStoriesChinese, packed into 32x32 grids (1,024 chars each). Vocab: top 4,000 most frequent CJK characters + punctuation.
v2.1 added directional neighbor loss. Instead of just predicting the center, the model also predicts each of its 4 neighbors with asymmetric weights: West=1.0 (you just read that char), East=0.75, South/North=0.25. This gives ~30x more supervision per forward pass and bakes in left-to-right reading order.
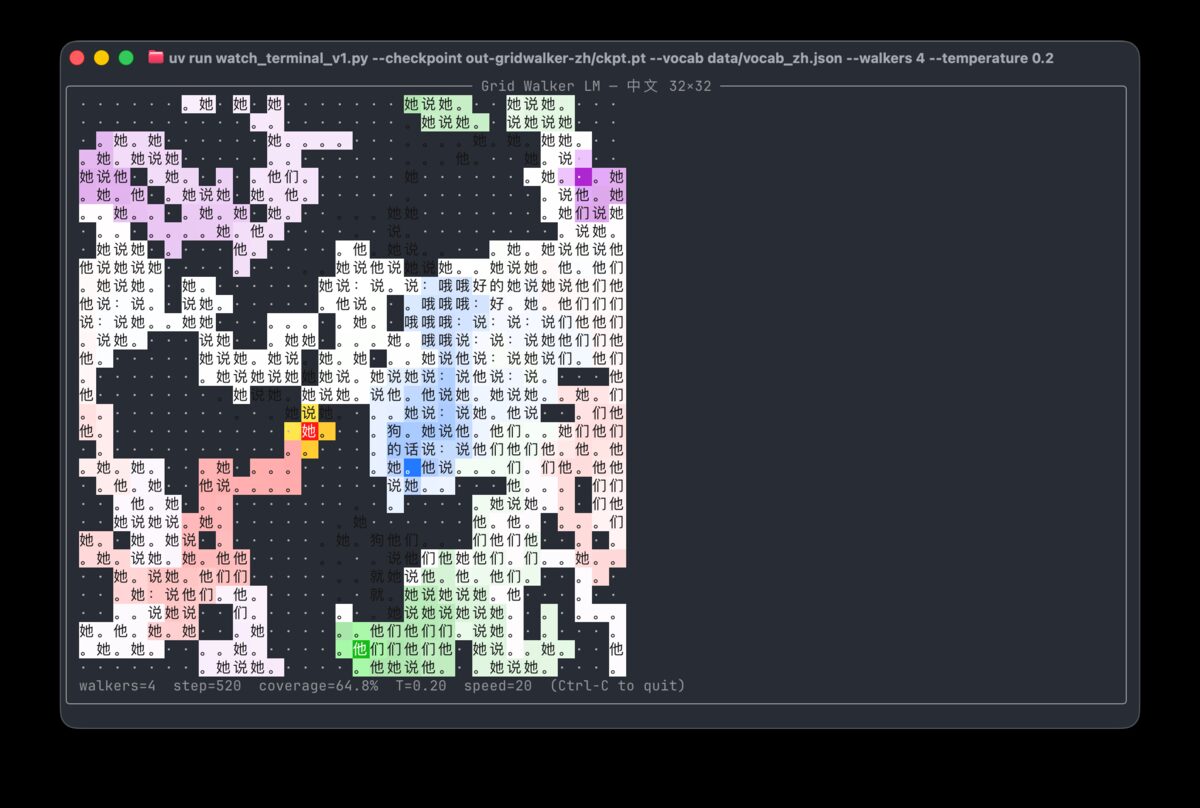

The multi-agent version is interesting. Four walkers roaming the same grid simultaneously, each one updating tiles based on what its neighbors already wrote. The text ends up being a collaboration between agents that never communicate directly, only through the grid itself.
v3: Async Cellular Automaton
Completely scrapped the walker concept. New idea: treat the grid as a cellular automaton. Each step, pick a random (x, y), read a manhattan-radius-5 diamond (61 cells), predict the center. No position embeddings, no causal attention. Just a bidirectional transformer over the 61-cell patch with slot embeddings.
Training uses a masked-diffusion approach (inspired by MD4 / Sahoo et al 2024). For each example, sample a noise level t~Uniform[0,1], mask each cell with probability t, always mask center, train cross-entropy on masked positions only. This exposes the model to every fill level, from nearly empty to nearly full, which exactly matches how inference works since the grid starts empty and fills up.
| Variant | Data | Vocab | Params | Hardware | Val Loss |
|---|---|---|---|---|---|
| v3-zh | TinyStoriesChinese | 4,002 (char) | 29M | A100 | 3.73 |
| v3-en | TinyStories | 50,258 (GPT-2 BPE) | 76M | A100 | 4.07 |
| v3-fineweb | Fineweb-Edu 10BT | 50,258 (GPT-2 BPE) | 162M | 2x H100 | 5.78 |
The fineweb run was the most ambitious. 162M params, 80k iterations, 2x H100 NVL for ~3 hours, cost about $16. Loss plateaued in the last 5k iters so it was likely compute-saturated at that scale.
The self-healing is the most interesting part. You can "bomb" a region, clear a chunk of cells to blank, and the surrounding context pulls coherent text back into the gap. The model doesn't know anything was destroyed. It just sees empty neighbors and fills them in based on what's around them.